The escalation package by Kristian Brock. Documentation
is hosted at https://brockk.github.io/escalation/
Introduction
The continual reassessment method (CRM) was introduced by O’Quigley, Pepe, and Fisher (1990). It has proved to be a truly seminal dose-finding design, spurring many revisions, variants and imitations.
Summary of the CRM Design
Pinning a finger on what is the CRM design is complicated because there have been so many versions over the years.
At its simplest, the CRM is a dose-escalation design that seeks a dose with probability of toxicity closest to some pre-specified target toxicity rate, , in an homogeneous patient group. The hallmark that unifies the CRM variants is the assumption that the probability of toxicity, , at the th dose, , can be modelled using a smooth mathematical function:
where is a general vector of parameters. Priors are specified on , and the dose with posterior estimate of closest to is iteratively recommended to the next patient(s).
Different variants of the CRM use different forms for . We consider those briefly now.
Hyperbolic tangent model
O’Quigley, Pepe, and Fisher (1990) first introduced the method using
with an exponential prior was placed on .
Toxicity skeletons and standardised doses
The
dose variables in the models above do not reflect the raw dose
quantities given to patients. For example, if the dose is 10mg, we do
not use x=10. Instead, a skeleton containing
estimates of the probabilities of toxicity at the doses is identified.
This skeleton could reflect the investigators’ prior expectations of
toxicities at all of the doses; or it could reflect their expectations
for some of the doses with the others interpolated in some plausible
way. The
are then calculated so that the model-estimated probabilities of
toxicity with the parameters taking their prior mean values match the
skeleton. This will be much clearer with an example.
In a five dose setting, let the skeleton be . That is, the investigators believe before the trial commences that the probbaility of toxicity at the second dose is 10%, and so on. Let us assume that we are using a one-parameter logistic model with and . Then we require that
i.e.
This yields the vector of standardised doses . Equivalent transformations can be derived for the other model forms. The are then used as covariates in the model-fitting. CRM users specify their skeleton, , and their parameter priors. From these, the software calculates the . The actual doses given to patients in SI units do not actually feature in the model.
Implementation in escalation
escalation simply aims to give a common interface to
dose-selection models to facilitate a grammar for specifying
dose-finding trial designs. Where possible, it delegates the
mathematical model-fitting to existing R packages. There are several R
packages that implement CRM models. The two used in
escalation are the dfcrm package (Y. K. Cheung 2011; K. Cheung 2013); and the
trialr package (Brock 2019,
2020). They have different strengths and weaknesses, so are
suitable to different scenarios. We discuss those now.
dfcrm
dfcrm
offers:
- the empiric model with normal prior on ;
- the one-parameter logistic model with normal prior on .
dfcrm models are fit in escalation using
the get_dfcrm function. Examples are given below.
trialr
trialr
offers:
- the empiric model with normal prior on ;
- the one-parameter logistic model with normal prior on ;
- the one-parameter logistic model with gamma prior on ;
- the two-parameter logistic model with normal priors on and .
trialr models are fit in escalation using
the get_trialr_crm function.
Let us commence by replicating an example from p.21 of Y. K. Cheung (2011). They choose the following parameters:
Let us define a model fitter using the dfcrm
package:
library(escalation)
model1 <- get_dfcrm(skeleton = skeleton, target = target, model = 'logistic',
intcpt = a0, scale = beta_sd)and a fitter using the trialr package:
model2 <- get_trialr_crm(skeleton = skeleton, target = target, model = 'logistic',
a0 = a0, beta_mean = 0, beta_sd = beta_sd)Names for the function parameters skeleton,
target, and model are standardised by
escalation because they are fundamental. Further parameters
(i.e. those in the second lines of each of the above examples) are
passed onwards to the model-fitting functions in dfcrm and
trialr. You can see that some of these parameter names vary
between the approaches. E.g., what dfcrm calls the
intcpt, trialr calls a0. Refer to
the documentation of the crm function in dfcrm
and stan_crm in trialr for further
information.
We then fit those models to the notional outcomes described in the source text:
The dose recommended by each of the models for the next patient is:
fit1 %>% recommended_dose()
#> [1] 4
fit2 %>% recommended_dose()
#> [1] 4Thankfully, the models agree. They advocate staying at dose 4, wary of the toxicity already seen at dose 5.
If we take a summary of each model fit:
fit1 %>% summary()
#> # A tibble: 6 × 9
#> dose tox n empiric_tox_rate mean_prob_tox median_prob_tox admissible
#> <ord> <dbl> <dbl> <dbl> <dbl> <dbl> <lgl>
#> 1 NoDose 0 0 0 0 0 TRUE
#> 2 1 0 0 NaN 0.00768 0.00768 TRUE
#> 3 2 0 0 NaN 0.0265 0.0265 TRUE
#> 4 3 0 2 0 0.0817 0.0817 TRUE
#> 5 4 0 1 0 0.182 0.182 TRUE
#> 6 5 1 2 0.5 0.331 0.331 TRUE
#> # ℹ 2 more variables: recommended <lgl>, Skeleton <dbl>
fit2 %>% summary()
#> # A tibble: 6 × 9
#> dose tox n empiric_tox_rate mean_prob_tox median_prob_tox admissible
#> <ord> <dbl> <dbl> <dbl> <dbl> <dbl> <lgl>
#> 1 NoDose 0 0 0 0 0 TRUE
#> 2 1 0 0 NaN 0.0300 0.00731 TRUE
#> 3 2 0 0 NaN 0.0633 0.0255 TRUE
#> 4 3 0 2 0 0.128 0.0791 TRUE
#> 5 4 0 1 0 0.219 0.178 TRUE
#> 6 5 1 2 0.5 0.340 0.326 TRUE
#> # ℹ 2 more variables: recommended <lgl>, Skeleton <dbl>We can see that they closely agree on model estimates of the
probability of toxicity at each dose. Note that the median perfectly
matches the mean in the dfcrm fit because it assumes a
normal posterior distribution on
.
In contrast, the trialr class uses Stan to fit
the model using Hamiltonian Monte Carlo sampling. The posterior
distributions for the probabilities of toxicity are evidently non-normal
and positively-skewed because the median estimates are less than the
mean estimates.
Let us imagine instead that we want to fit the empiric model. That
simply requires we change the model variable and adjust the
prior parameters:
model3 <- get_dfcrm(skeleton = skeleton, target = target, model = 'empiric',
scale = beta_sd)
model4 <- get_trialr_crm(skeleton = skeleton, target = target, model = 'empiric',
beta_sd = beta_sd)Fitting each to the same set of outcomes yields:
fit3 %>% summary()
#> # A tibble: 6 × 9
#> dose tox n empiric_tox_rate mean_prob_tox median_prob_tox admissible
#> <ord> <dbl> <dbl> <dbl> <dbl> <dbl> <lgl>
#> 1 NoDose 0 0 0 0 0 TRUE
#> 2 1 0 0 NaN 0.00701 0.00701 TRUE
#> 3 2 0 0 NaN 0.0299 0.0299 TRUE
#> 4 3 0 2 0 0.101 0.101 TRUE
#> 5 4 0 1 0 0.219 0.219 TRUE
#> 6 5 1 2 0.5 0.372 0.372 TRUE
#> # ℹ 2 more variables: recommended <lgl>, Skeleton <dbl>
fit4 %>% summary()
#> # A tibble: 6 × 9
#> dose tox n empiric_tox_rate mean_prob_tox median_prob_tox admissible
#> <ord> <dbl> <dbl> <dbl> <dbl> <dbl> <lgl>
#> 1 NoDose 0 0 0 0 0 TRUE
#> 2 1 0 0 NaN 0.0309 0.00766 TRUE
#> 3 2 0 0 NaN 0.0668 0.0318 TRUE
#> 4 3 0 2 0 0.142 0.105 TRUE
#> 5 4 0 1 0 0.249 0.225 TRUE
#> 6 5 1 2 0.5 0.381 0.378 TRUE
#> # ℹ 2 more variables: recommended <lgl>, Skeleton <dbl>In this example, the model estimates are broadly consistent across
methodology and model type. However, this is not the general case. To
illustrate this point, let us examine a two parameter logistic model fit
using trialr (note: this model is not implemented in
dfcrm):
model5 <- get_trialr_crm(skeleton = skeleton, target = target, model = 'logistic2',
alpha_mean = 0, alpha_sd = 2, beta_mean = 0, beta_sd = 1)
fit5 <- model5 %>% fit(outcomes)
fit5 %>% summary()
#> # A tibble: 6 × 9
#> dose tox n empiric_tox_rate mean_prob_tox median_prob_tox admissible
#> <ord> <dbl> <dbl> <dbl> <dbl> <dbl> <lgl>
#> 1 NoDose 0 0 0 0 0 TRUE
#> 2 1 0 0 NaN 0.0347 0.00394 TRUE
#> 3 2 0 0 NaN 0.0567 0.0171 TRUE
#> 4 3 0 2 0 0.105 0.0625 TRUE
#> 5 4 0 1 0 0.203 0.164 TRUE
#> 6 5 1 2 0.5 0.411 0.384 TRUE
#> # ℹ 2 more variables: recommended <lgl>, Skeleton <dbl>Now the estimate of toxicity at the highest dose is high relative to the other models. The extra free parameter in the two-parameter model offers more flexibility. There has been a debate in the literature about one-parameter vs two-parameter models (and possibly more). It is generally accepted that a single parameter model is too simplistic to accurately estimate over the entire dose range. However, it will be sufficient to identify the dose closest to , and if that is the primary objective of the trial, the simplicity of a one-parameter model may be entirely justified. The interested reader is directed to O’Quigley, Pepe, and Fisher (1990) and Neuenschwander, Branson, and Gsponer (2008).
Note that the CRM does not natively implement stopping rules, so these classes on their own will always advocate trial continuance:
and identify each dose as admissible:
fit1 %>% dose_admissible()
#> [1] TRUE TRUE TRUE TRUE TRUEThis behaviour can be altered by appending classes to advocate stopping for consensus:
model6 <- get_trialr_crm(skeleton = skeleton, target = 0.3, model = 'empiric',
beta_sd = 1) %>%
stop_when_n_at_dose(dose = 'recommended', n = 6)
fit6 <- model6 %>% fit('2NNN 3TTT 2NTN')
fit6 %>% continue()
#> [1] FALSE
fit6 %>% recommended_dose()
#> [1] 2Or for stopping under excess toxicity:
model7 <- get_trialr_crm(skeleton = skeleton, target = 0.3, model = 'empiric',
beta_sd = 1) %>%
stop_when_too_toxic(dose = 1, tox_threshold = 0.3, confidence = 0.8)
fit7 <- model7 %>% fit('1NTT 1TTN')
fit7 %>% continue()
#> [1] FALSE
fit7 %>% recommended_dose()
#> [1] NA
fit7 %>% dose_admissible()
#> [1] FALSE FALSE FALSE FALSE FALSEOr both:
model8 <- get_trialr_crm(skeleton = skeleton, target = 0.3, model = 'empiric',
beta_sd = 1) %>%
stop_when_n_at_dose(dose = 'recommended', n = 6) %>%
stop_when_too_toxic(dose = 1, tox_threshold = 0.3, confidence = 0.8)For more information, check the package README and the other vignettes.
dfcrm vs trialr
So which method should you use? The answer depends on how you plan to use the models.
The trialr classes produce posterior samples:
fit7 %>%
prob_tox_samples(tall = TRUE) %>%
head()
#> # A tibble: 6 × 3
#> .draw dose prob_tox
#> <chr> <chr> <dbl>
#> 1 1 1 0.658
#> 2 2 1 0.645
#> 3 3 1 0.701
#> 4 4 1 0.687
#> 5 5 1 0.674
#> 6 6 1 0.553and these facilitate flexible visualisation:
library(ggplot2)
library(dplyr)
fit7 %>%
prob_tox_samples(tall = TRUE) %>%
mutate(.draw = .draw %>% as.integer()) %>%
filter(.draw <= 200) %>%
ggplot(aes(dose, prob_tox)) +
geom_line(aes(group = .draw), alpha = 0.2)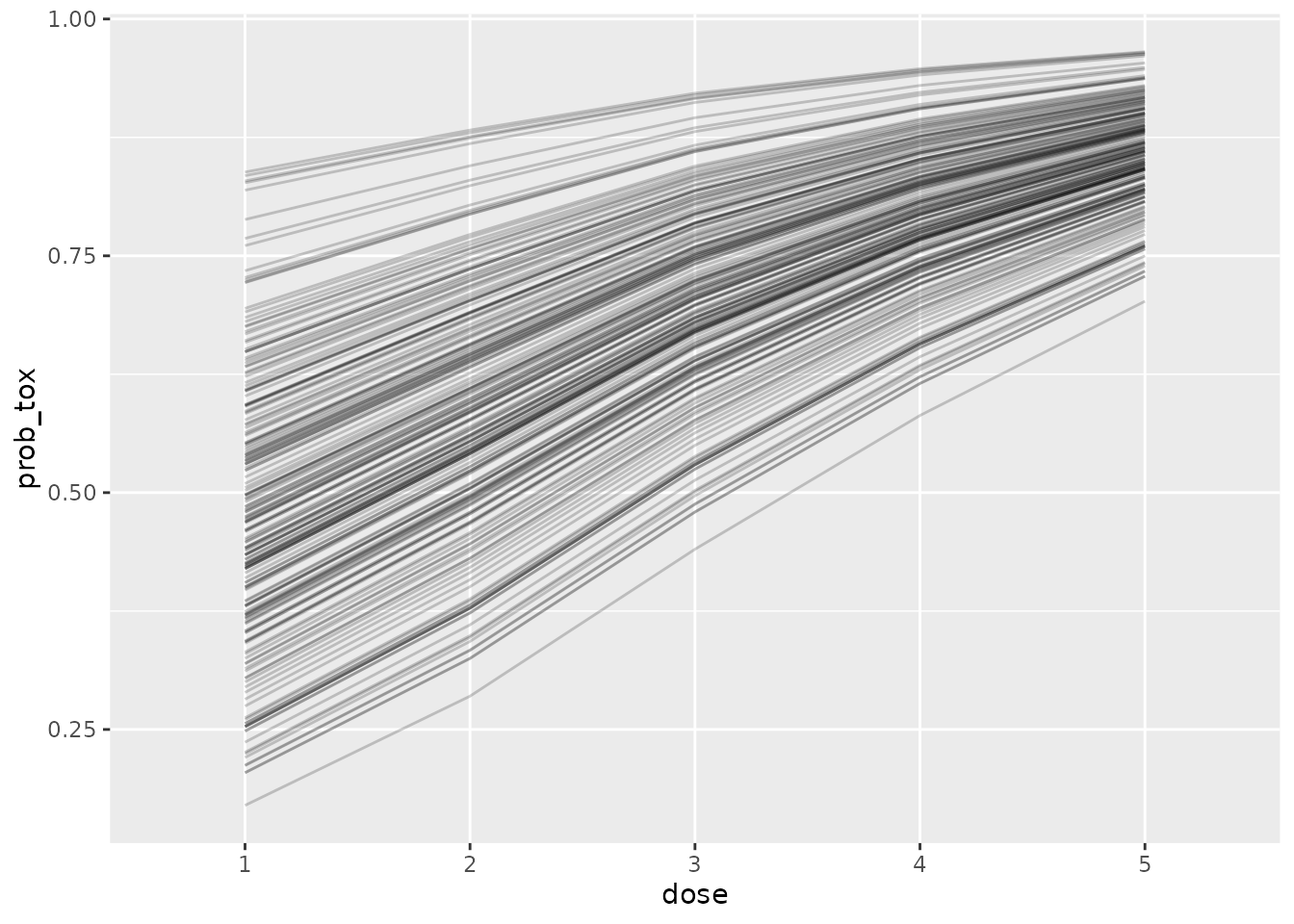
However, MCMC sampling is an expensive computational procedure
compared to the numerical integration used in dfcrm. If you
envisage fitting lots of models, perhaps in simulations or dose-paths
(see below) and favour a model offered by dfcrm, we
recommend using get_dfcrm. However, if you favour a model
only offered by trialr, or if you are willing for
calculation to be slow in order to get posterior samples, then use
trialr.
Dose paths
We can use the get_dose_paths function in
escalation to calculate exhaustive model recommendations in
response to every possible set of outcomes in future cohorts. For
instance, at the start of a trial using an empiric CRM, we can examine
all possible paths a trial might take in the first two cohorts of three
patients, starting at dose 2:
skeleton <- c(0.05, 0.12, 0.25, 0.40, 0.55)
target <- 0.25
beta_sd <- 1
model <- get_dfcrm(skeleton = skeleton, target = target, model = 'empiric',
scale = beta_sd)
paths <- model %>% get_dose_paths(cohort_sizes = c(3, 3), next_dose = 2)
graph_paths(paths)We see that the design would willingly skip dose 3 if no tox is seen
in the first cohort. This might warrant suppressing dose-dkipping by
appending a dont_skip_doses(when_escalating = TRUE)
selector.
Dose-paths can also be run for in-progress trials where some outcomes have been established. For more information on working with dose-paths, refer to the dose-paths vignette.
Simulation
We can use the simulate_trials function to calculate
operating characteristics for a design. Let us use the example above and
tell the design to stop when the lowest dose is too toxic, when 9
patients have already been evaluated at the candidate dose, or when a
sample size of
is reached:
model <- get_dfcrm(skeleton = skeleton, target = target, model = 'empiric',
scale = beta_sd) %>%
stop_when_too_toxic(dose = 1, tox_threshold = target, confidence = 0.8) %>%
stop_when_n_at_dose(dose = 'recommended', n = 9) %>%
stop_at_n(n = 24)For the sake of speed, we will run just fifty iterations:
num_sims <- 50In real life, however, we would naturally run many thousands of iterations. Let us investigate under the following true probabilities of toxicity:
sc1 <- c(0.25, 0.5, 0.6, 0.7, 0.8)The simulated behaviour is:
set.seed(123)
sims <- model %>%
simulate_trials(num_sims = num_sims, true_prob_tox = sc1, next_dose = 1)
sims
#> Number of iterations: 50
#>
#> Number of doses: 5
#>
#> True probability of toxicity:
#> 1 2 3 4 5
#> 0.25 0.50 0.60 0.70 0.80
#>
#> Probability of recommendation:
#> NoDose 1 2 3 4 5
#> 0.32 0.62 0.06 0.00 0.00 0.00
#>
#> Probability of administration:
#> 1 2 3 4 5
#> 0.6049 0.2537 0.0293 0.1122 0.0000
#>
#> Sample size:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 3.0 9.0 12.0 12.3 18.0 21.0
#>
#> Total toxicities:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 2.00 2.25 4.50 4.82 7.00 9.00
#>
#> Trial duration:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 1.129 8.723 12.861 12.798 17.758 26.542We see that the chances of stopping for excess toxicity and
recommending no dose is about 1-in-4. Dose 1 is the clear favourite to
be identified. Interestingly, the stop_when_n_at_dose class
reduces the expected sample size to 12-13 patints. Without it:
get_dfcrm(skeleton = skeleton, target = target, model = 'empiric',
scale = beta_sd) %>%
stop_when_too_toxic(dose = 1, tox_threshold = target, confidence = 0.8) %>%
stop_at_n(n = 24) %>%
simulate_trials(num_sims = num_sims, true_prob_tox = sc1, next_dose = 1)
#> Number of iterations: 50
#>
#> Number of doses: 5
#>
#> True probability of toxicity:
#> 1 2 3 4 5
#> 0.25 0.50 0.60 0.70 0.80
#>
#> Probability of recommendation:
#> NoDose 1 2 3 4 5
#> 0.40 0.50 0.08 0.02 0.00 0.00
#>
#> Probability of administration:
#> 1 2 3 4 5
#> 0.6250 0.2297 0.0473 0.0980 0.0000
#>
#> Sample size:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 3.00 9.00 24.00 17.76 24.00 24.00
#>
#> Total toxicities:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 2.00 5.25 7.00 6.64 9.00 12.00
#>
#> Trial duration:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 1.05 8.22 19.40 17.66 25.41 32.88expected sample size is much higher and the chances of erroneously stopping early are also higher. These phenomena would justify a wider simulation study in a real situation.
For more information on running dose-finding simulations, refer to the simulation vignette.